Abstract
Method
Overview
I-HallA evaluates image hallucination by leveraging VQA to verify factual details not explicitly mentioned in the text prompts. The pipeline involves generating images from TTI models, creating factual reasoning with GPT-4o, and forming question-answer sets to assess the hallucinations.
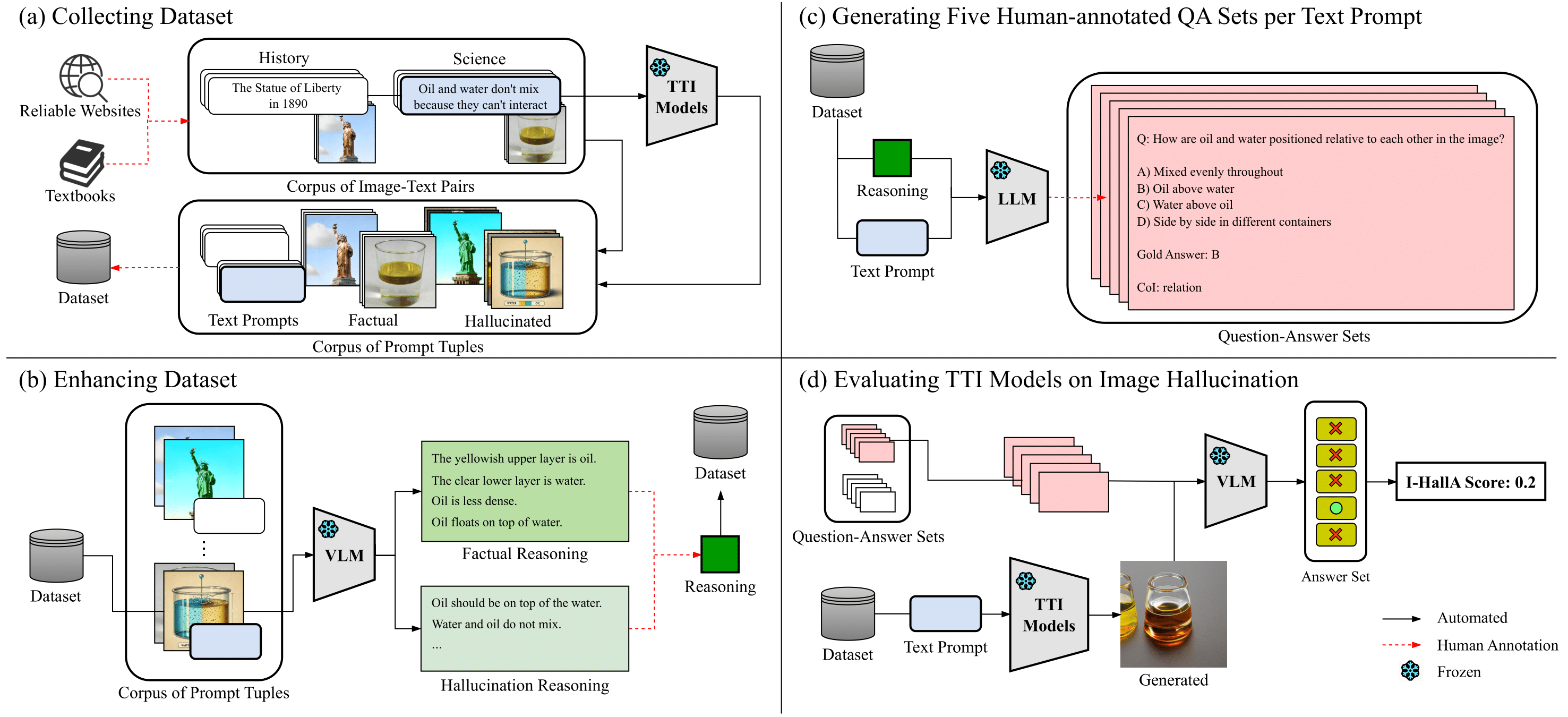
Dataset Construction
The I-HallA v1.0 dataset includes prompts extracted from five science and history textbooks, chosen for their curated and fact-verified content. Each prompt is paired with factual images and hallucinated images generated by TTI models. The benchmark evaluates whether the images align with factual data based on generated QA sets.
Benchmark Structure
- Prompt & Image Collection: Textbook captions and figures serve as sources for factual prompts and images.
- Enhancement Using GPT-4o: GPT-4o adds reasoning to the prompt-image pairs to validate factuality.
- QA Set Generation: Multiple-choice QA sets are formed to assess image hallucinations, reviewed and refined by human annotators.
Results
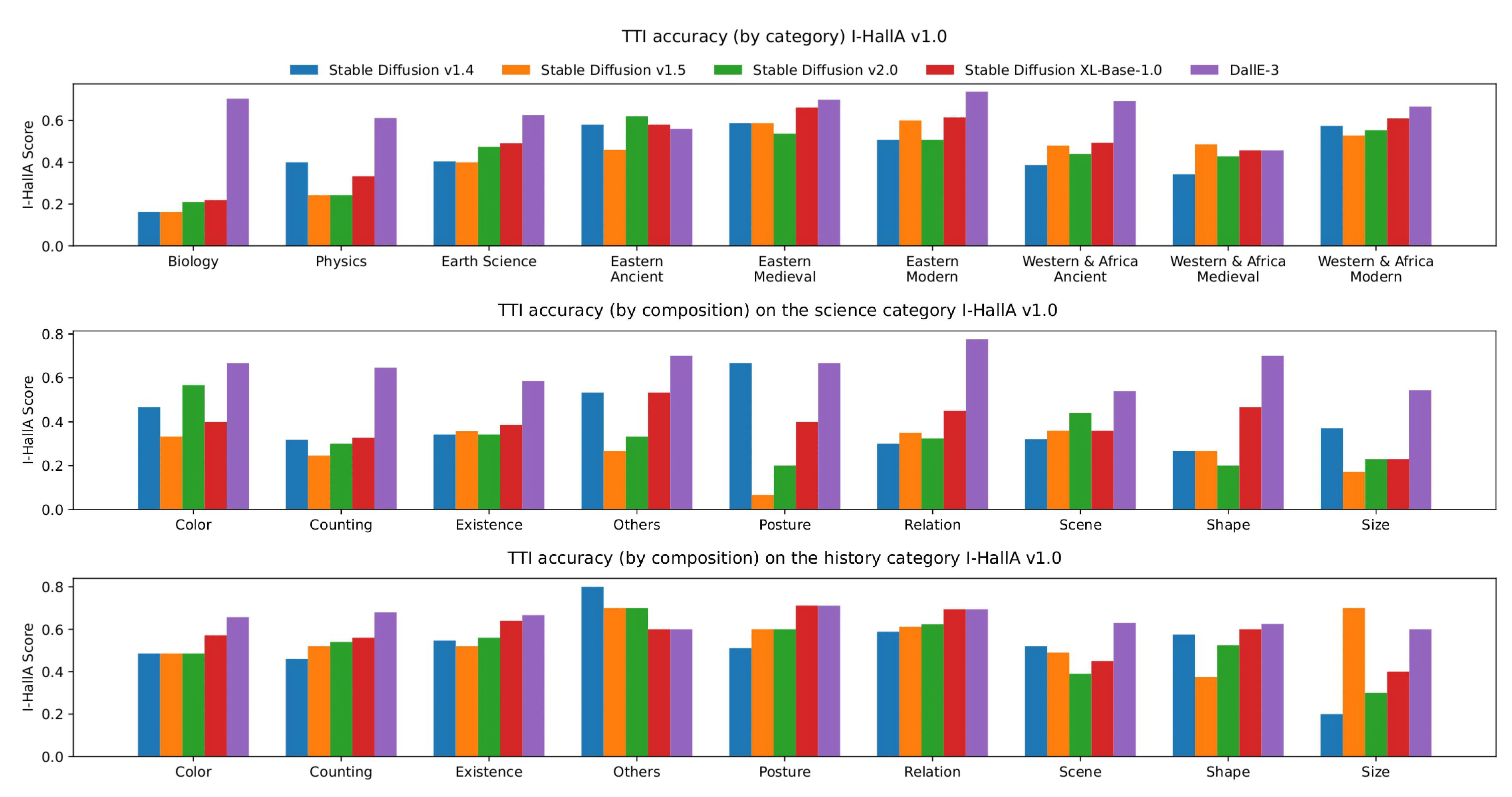
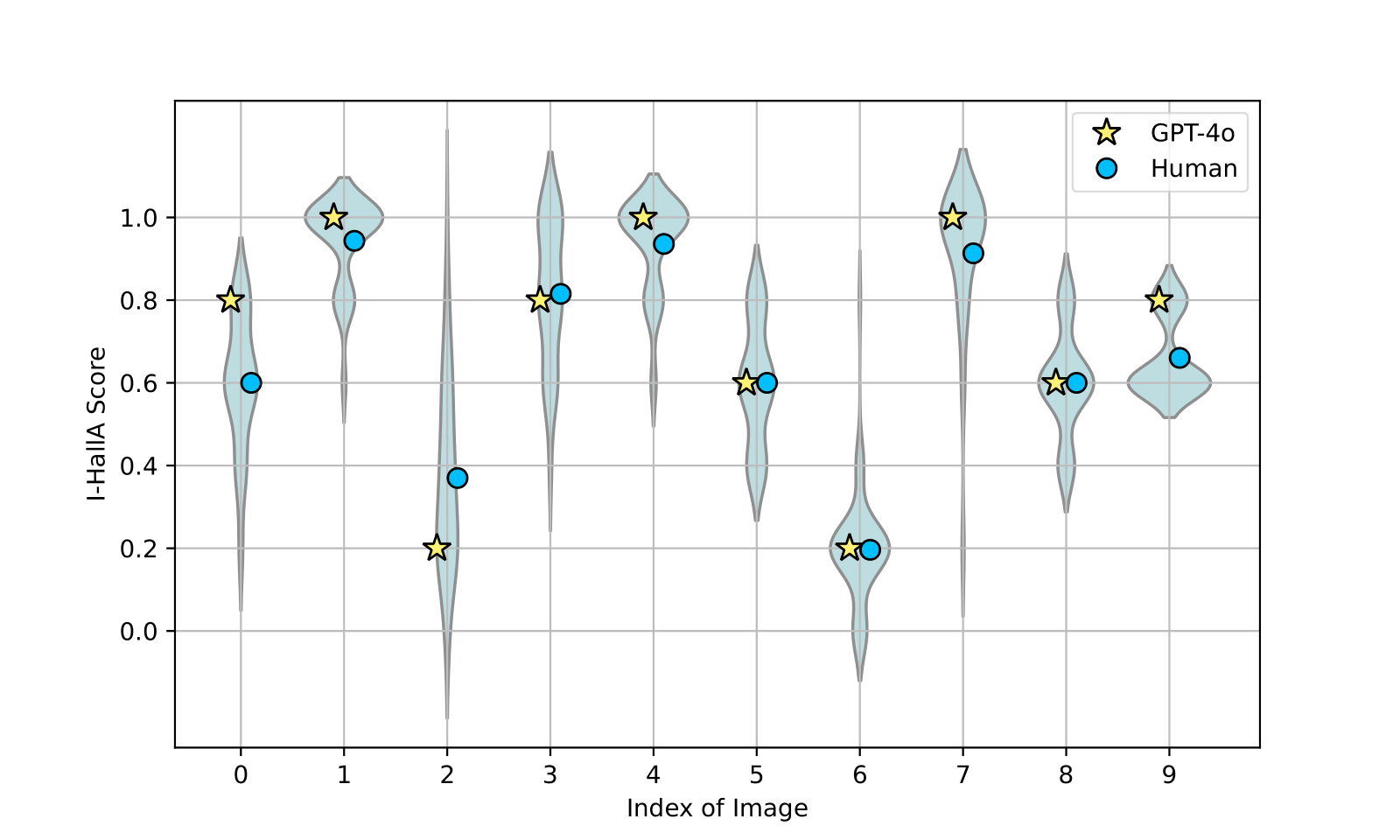 I-HallA was applied to five models: DALL-E 3, Stable Diffusion v1.4, v1.5, v2.0, and SD XL-base. DALL-E 3 demonstrated the lowest hallucination rates, while all models exhibited issues with factual consistency. I-HallA scores correlate highly with human assessments, confirming the metric’s reliability.
I-HallA was applied to five models: DALL-E 3, Stable Diffusion v1.4, v1.5, v2.0, and SD XL-base. DALL-E 3 demonstrated the lowest hallucination rates, while all models exhibited issues with factual consistency. I-HallA scores correlate highly with human assessments, confirming the metric’s reliability.
Conclusion
This paper introduces a new method for evaluating image hallucination in TTI models. By leveraging factual reasoning and VQA, I-HallA effectively measures the factuality of generated images. The strong correlation with human judgment shows promise for its future application in improving the factual accuracy of text-to-image models.
Citation
@article{ihalla,
author = {Youngsun Lim and
Hojun Choi and
Hyunjung Shim},
title = {Evaluating Image Hallucination in Text-to-Image Generation with Question-Answering},
Conference = {AAAI},
year = {2025},
}